Steve Boals ist bei Ephesoft für die Technologiepartner im Bereich robotische Prozessautomatisierung – kurz RPA – zuständig. In diesem Webinar erläutert er Ihnen vier entscheidende Elemente, durch die Sie das automatisierte Auslesen und Bearbeiten von Dokumenten verbessern. Anhand der richtigen Plattform für Dokumentenintelligenz demonstriert er, wie Sie die Automatisierung und die Effizienz durch robotische Software steigern.
Automatisiertes Erkennen von Inhalten
Interessanterweise basiert eine der fortschrittlichsten Technologien zur Prozessautomatisierung auf Software, bei der jahrzehntealte Technologie in ihrer einfachsten Form eingesetzt wird, um Dokumentenprozesse zu automatisieren. Plattformen für intelligente Dokumentenerfassung bieten jedoch mehr als nur optische Zeichenerkennung (OCR): Sie erweitern die Möglichkeiten Ihrer RPA und bieten intelligentes Auslesen von Dokumenten. Bevor wir uns diese Lösung ansehen, schauen wir uns zunächst den Status quo und die Herausforderungen an.
Alle Organisationen haben mit Dokumenten zu kämpfen, entweder mit Unterlagen in Papierform, mit digitalen Dokumenten oder mit einer Kombination aus beiden. Im Bereich der RPA sind dokumentenlastige Prozesse ein wesentlicher Schwerpunkt. Doch damit Dokumente verarbeitet und die darin enthaltenen unstrukturierten Inhalte erkannt werden, benötigt die Software klaren, freien Durchblick, um die Dokumentenströme auszuwerten, intelligente Entscheidungen auf Grundlage der Daten zu treffen und bei Bedarf einen Menschen einzuschalten.
Beweggründe für die Anwendung von RPA
Die Everest Group hat mit ihrem „Smart RPA Enterprise Playbook“ einen ausgezeichneten Leitfaden für die RPA veröffentlicht. Wird das automatisierte Auslesen von Dokumenten mittels Software verbessert, ergibt sich unter Umständen ein Multiplikatoreffekt, wenn Sie sich schwierige Dokumentenprozesse im Unternehmen vornehmen: Oftmals wirken sich minimale Anpassungen oder Verbesserungen deutlich auf eine Vielzahl der genannten Faktoren aus.
Die Bearbeitung von Dokumenten durch den Menschen
Üblicherweise empfangen Organisationen täglich Dokumente unterschiedlichsten Ursprungs. Dadurch erstrecken sich die Probleme auf viele Kanäle und die Organisation haben Schwierigkeiten, effiziente Abläufe für analoge – d. h. papiergebundene – und digitale Dokumente festzulegen, ganz zu schweigen von effizienten Prozessen für Dokumente aus so unterschiedlichen Quellen wie Faxgerät, Scanner, Kopiergerät, Smartphone oder E-Mail. Normalerweise nutzen die Mitarbeiter einer Organisation eine Fülle von – manuellen wie automatisierten – Workflows, um eingehende Dokumente zu bearbeiten. Einige Mitarbeiter erweitern oder automatisieren mithilfe von Technologien einen Teil der Workflows, doch die zentralen Schritte bleiben dieselben:
- Die empfangenen Dokumente werden gebündelt, getrennt, sortiert und weitergeleitet.
- Es erfolgt die Identifizierung wichtiger Daten.
- Daten werden extrahiert und eingeben.
- Anschließend erfolgt unter Umständen die Validierung der Daten und der Dokumente. Allerdings fehlt dieser Schritt bei vielen Organisationen, sodass zusätzliche Probleme entstehen.
Mit etwas Glück landen die Daten und die Dokumente schließlich in den richtigen Systemen.
Bearbeitung von Dokumenten durch robotische Software
Wenn wir nur den Menschen durch Software ersetzen, ohne das Auslesen zu verbessern, und wenn wir uns auf veraltete OCR-Technologie stützen, verursachen wir digitales Chaos. Die Bots können die einzelnen Schritte der Dokumentenprozesse nicht bewältigen, ihnen fehlt einfach die Intelligenz, um den Workflow zu meistern. Wenn wir unseren Bots nur schmutzige Brillen aufsetzen, fehlt ihnen der Durchblick, sodass optimale Effizienz und größtmögliche Automatisierung nicht erreicht werden. Welche Hindernisse sind zu überwinden?
Herausforderung OCR
Die meisten OCR-Technologien auf dem Markt sind bereits zehn bis zwölf Jahre alt. Ihren ursprünglichen Zweck – die Konvertierung von Bildern in Text – erfüllen sie gut. Doch die Textausgabe der OCR ist erst der Anfang oder die Grundlage für die Methoden, die bei Dokumentenprozessen angewendet werden. Standardprogramme bieten keinen Kontext, keine Identifizierung von Dokumententypen und keine Extraktion der Daten von Interesse. Viele Produkte nehmen anhand der Textebene einen einfachen Musterabgleich vor und verwenden Vorlagen oder Zonen in Dokumenten für die Datenextraktion. Diese Technologien sind bei nur teilweise strukturierten oder völlig unstrukturierten Inhalten nicht effektiv. Sie können zu hohen Fehlerraten bei der Klassifizierung von Dokumenten führen. Beim Umgang mit Ausnahmen erfordern sie häufiges Eingreifen durch den Menschen. Diese Technologien benötigen zusätzliche Intelligenz, damit die vollständige Automatisierung unterstützt wird. Für die komplexen Workflows, durch die eine Implementierung der RPA eine ganz neue Stufe erreicht, ist eine intelligentere Plattform erforderlich. Dadurch lassen sich bei der Automatisierung bessere Ergebnisse erzielen und die Anzahl der Ausnahmen verringern.
Intelligente RPA-Plattform
Wie der Leitfaden von Everest zeigt, basiert intelligente RPA auf einer Verknüpfung der unterschiedlichsten Technologien, die eine Erweiterung der Automatisierung ermöglichen. Die Digital Workforce arbeitet dadurch intelligenter, schneller, genauer und erfordert weniger Eingreifen durch den Menschen.
Nachdem wir die Herausforderungen nun kennen, stellt sich die Frage, wie wir optimale Ergebnisse erzielen. Durch welche entscheidenden Elemente lässt sich die Dokumentenintelligenz der Software verbessern? Im Folgenden erläutert Steve Boals die entscheidenden vier Bereiche, die Bestandteil einer klaren Strategie für das automatisierte Auslesen von Dokumenten sein sollten.
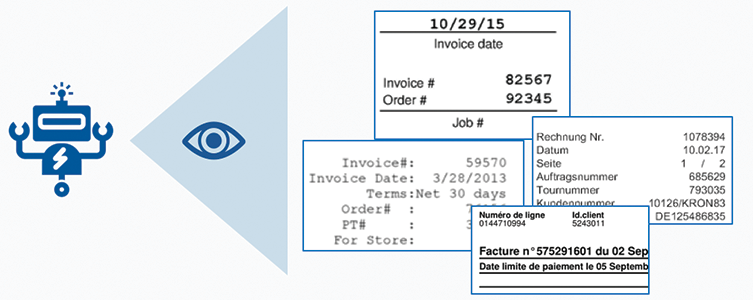
1. Verzichten Sie auf veraltete OCR-Technologie: Ein entscheidender Aspekt besteht darin, die veraltete Standard-OCR hinter sich zu lassen und stattdessen eine intelligente Erfassungs-Plattform einzusetzen, die das Auslesen von Dokumenten erweitert.
Intelligente Erfassungs-Plattformen von heute betrachten Dokumente nicht als reinen Text, sondern als eine Reihe unterschiedlicher Dimensionen. Werden Dokumente auf diese Weise analysiert, verbessert sich die Genauigkeit und es werden die gewünschten Ergebnisse erzielt. Zudem ermöglicht dieser Ansatz, innovative Extraktionsverfahren einzusetzen, die über den reinen Textabgleich hinausgehen. Diese erweiterten Extraktionsregeln erlauben es, auf starre Vorlagen für die Verarbeitung zu verzichten und stattdessen unterschiedliche Dokumentenvarianten zu berücksichtigen. Außerdem lassen sich die Regeln auf das gesamte Dokument anwenden. Innovative Plattformen können zudem auch komplexere Dokumententypen bearbeiten.
2. Maschinelles Lernen: Mithilfe von Beispieldokumenten kann maschinelles Lernen (ML) leicht eingerichtet werden. Laden Sie verschiedene Dokumententypen hoch und das System entwickelt ein Modell für die Identifizierung bzw. Klassifizierung. Neben der einfacheren Einrichtung für Administratoren bietet das ML auch einen Trainingsmechanismus für die Bediener – ganz gleich, ob Software oder Mensch. Werden bestimmte Dokumente nicht erkannt, können sie hinzugefügt werden, damit künftig die Bearbeitung dieses Dokumententyps unterstützt wird.
Dokumente sind komplex und können nicht wie ein normales Bild behandelt werden. Erfahrungsgemäß gibt es Formulartypen, die nahezu identisch sind, abgesehen von der Formatierung oder vom Text. ML-Modelle, die zwar gut zwischen Löwen und Hunden unterscheiden können, erfassen solche subtilen Unterschiede oftmals nicht. Für unsere Zielsetzung ist daher eine Kombination aus Textanalyse und mehrstufigem Ansatz erforderlich.
Eine Analyse, die über das Bild oder den Text hinausgeht, ist eine wichtige Voraussetzung. Die Dokumentenintelligenz, auf die sich die Digital Workforce stützt, muss sich auf Dimensionen der Dokumente konzentrieren, die über den reinen Text hinausgehen.
3. Drei Säulen der Dokumentenerfassung:
- Die erste und wichtigste Säule besteht in der Klassifizierung. Genau wie die Mitarbeiter eines Unternehmens Dokumente prüfen, wendet das System sein ML-Modell an und stellt so fest, wo ein Dokument endet und das Nächste beginnt. Das System klassifiziert oder identifiziert Dokumententypen automatisch, einschließlich aller darin enthaltenen Seiten. Dank dieser Funktion können Dokumente stapelweise erfasst werden, beispielsweise eine große PDF-Datei oder ein Papierstapel. Dabei übernimmt das System in kürzester Zeit sämtliche Aufgaben, die den Menschen viel Zeit und Mühe kosten würden.
- Sobald das System alle Dokumente in den zugeführten Seiten identifiziert hat, teilt es diese in einzelne Gruppen auf. Der Prozess ist vergleichbar mit dem Vorgehen eines Mitarbeiters, der einen Stapel an Dokumenten aufteilen soll. Wir bezeichnen dies als Trennen. Durch das Trennen von Dokumenten ist es möglich, am Ende des Prozesses einzelne Dokumente als Ergebnis auszugeben. Erfolgen Klassifizieren und Trennen mithilfe des maschinellen Lernens automatisiert, sind enorme Kosteneinsparungen und Effizienzsteigerungen möglich. Dies gilt insbesondere für PDF-Dateien, die mehrere Dokumente enthalten, oder für große Mengen an Dokumenten in Papierform. In diesem kombinierten Prozess erfolgt zudem die Vorbereitung der Dokumente auf nächsten Automatisierungsschritt.
- Die manuelle Dateneingabe ist der nächste Schritt, den wir mit unserem System übernehmen können. Durch die Anwendung fester Regeln, die mit der Klassifizierung verknüpft sind, können wir nun die gewünschten Daten automatisch aus dem Dokument extrahieren. Diese Regeln können sich je nach Dokument unterscheiden und variieren. Die Technologie macht eine manuelle Eingabe durch den Menschen überflüssig. Auch das Umbenennen von Dokumenten oder die Erstellung von Ordnern von Hand entfällt. Die Daten stehen der Digital Workforce nun zur weiteren Bearbeitung zur Verfügung.
4. Umgang mit Ausnahmen: Der letzte entscheidende Aspekt für eine erfolgreiche Automatisierung ist die Option „Telefonjoker“ – die Möglichkeit, die Frage an den Kollegen Mensch weiterzugeben. Wenn eine Ausnahme das Eingreifen des Menschen erfordert, sollte dies möglichst kontrolliert und nahtlos geschehen. Damit Ausnahmen validiert und bearbeitet werden können, benötigen Mensch und Software möglichst viele Informationen. Mit Smart Capture können Regeln erstellt werden, damit das ML-System fehlende Seiten, Daten schlechter Qualität und vom System nicht erwartete Daten erkennt. Durch diesen Validierungsprozess und die Bearbeitung von Ausnahmen werden fehlerhafte Daten eliminiert, Informationen formatiert und eine hohe Qualität sichergestellt. Dies ist der einzige Schritt, der das Eingreifen des Menschen erfordert. Anhand der in den Warteschlangen befindlichen Ausnahmen können die Systeme weiter trainiert werden – hierfür gibt es eine anwenderfreundliche ML-Schnittstelle.
Das robotische „Software-Sandwich“
Mit der richtigen Technologie entwickeln wir das, was ich gerne als „Software-Sandwich“ bezeichne. Diese Methode umfasst robotische Software als Ursprung der Dokumente, die dem Dokumentenprozess zuführt werden. Zudem gibt es die Möglichkeit, den Menschen zur Qualitätssicherung oder zur Bearbeitung von Ausnahmen hinzuzuziehen. Am Ende des Prozesses empfängt eine weitere robotische Software, die Ergebnisse. Auch dies ist eine einfache, nahtlose Methode und Schnittstelle, über die der Input erfolgt.
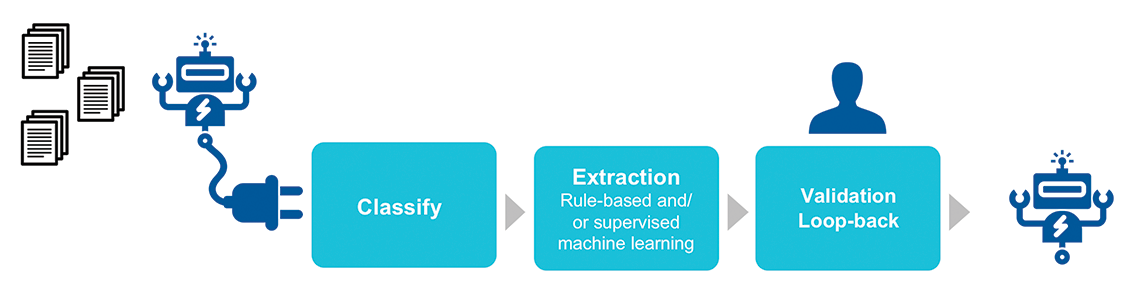
Das „Software-Sandwich“: Was umfasst die Lösung?
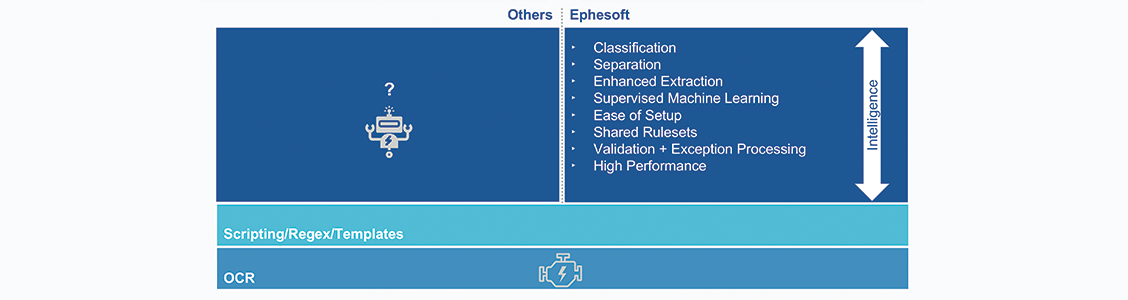
Wo finden wir diese vier entscheidenden Elemente? Ephesoft bietet diese und weitere Elemente, sodass Ihre Digital Workforce größeren Durchblick bei Dokumenten hat. Mit dem Ziel einer weiteren Vereinfachung und im Rahmen von automatisierten Workflows ermöglicht Ephesoft das automatische Auslesen der unstrukturierten Inhalte, die sich in Dokumenten befinden. Damit ermöglicht Ephesoft die Klassifizierung von Dokumententypen, die Trennung von PDF-Dateien und Bildern, die mehrere Dokumente enthalten, sowie die Extraktion der gewünschten Daten.
Wodurch unterscheidet sich die Lösung von Ephesoft? Wir ergänzen OCR und Musterabgleich als Grundlage durch eine zusätzliche Ebene künstlicher Intelligenz. Diese Features und Funktionen sind vergleichbar mit einem Upgrade der Automatisierungssoftware, mit dem Sie das Auslesen von Dokumenten und die Möglichkeiten für deren Bearbeitung erweitern.
Sehen das Demovideo
Erfahren Sie mehr:
Die Lösung: Dokumentenintelligenz durch RPA
UiPath: Aktivitäten von Ephesoft
Blue Prism: Integration des Visual Business Object (VBO) von Ephesoft
Kontaktieren Sie uns gerne für weitere Informationen.
