Introduction
This document provides Transact administrators with steps to configure the KV Page Process plugin, which allows you to classify documents based on keywords, also known as keyword-based classification.
This feature improves document classification based on user-defined static and dynamic keywords in the document. The KV Page Process plugin can be tailored to the specific needs of your organization.
Prerequisites
To configure and use the KV_PAGE_PROCESS plugin, the following conditions must be met:
- You will need a batch class with a document type configured. For detailed steps, refer to Add New Document Type.
- You will need to add the KV_PAGE_PROCESS plugin to the Extraction module for the batch class. For more detailed steps, refer to Configuring Plugins.
Configuring the Plugin
To implement keyword-based classification within Transact, you must first configure the plugin. To do so, perform the following steps:
- From the Batch Class Management screen, open your batch class.
The batch class opens with a list of document types.
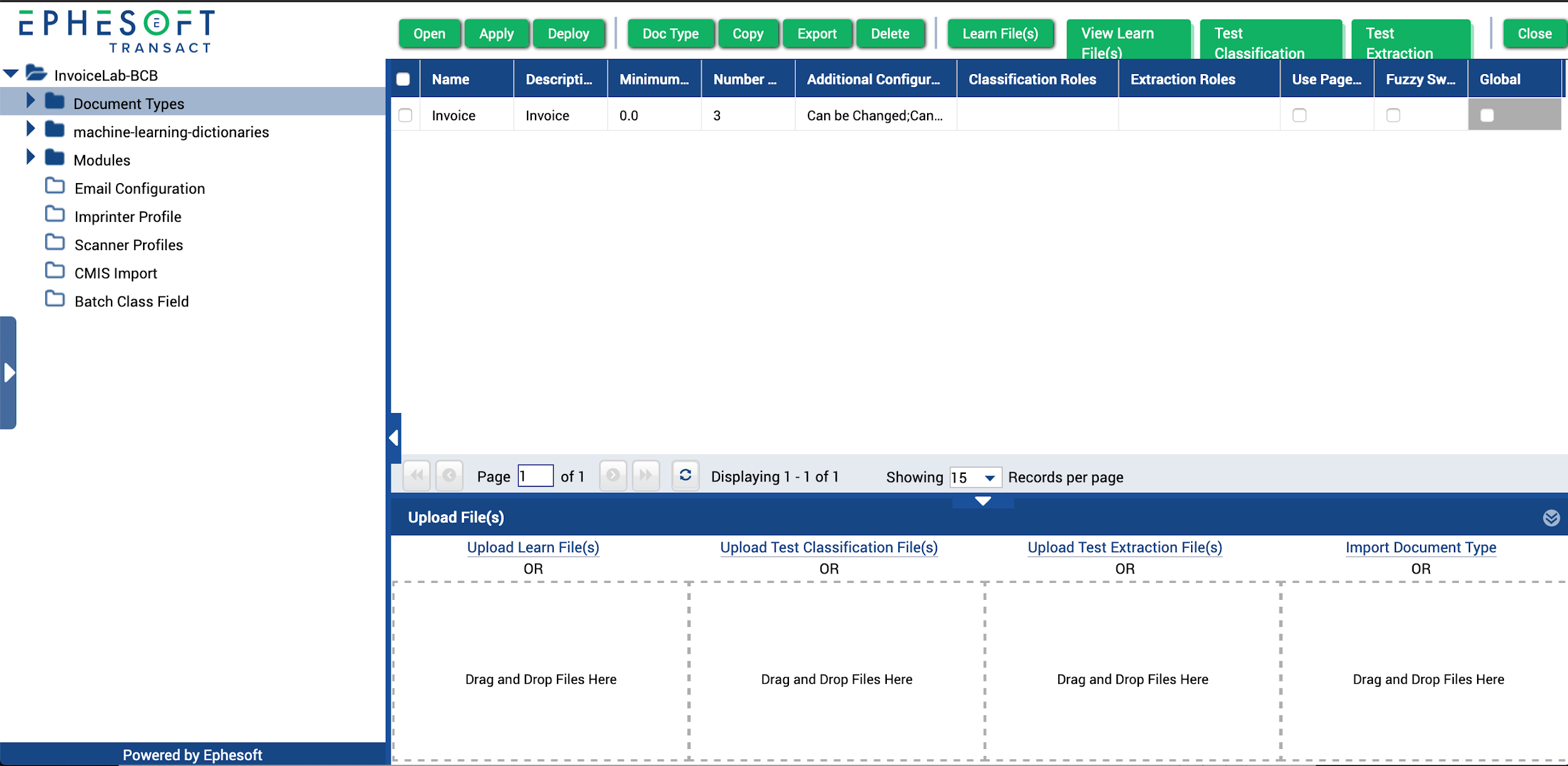
Figure 1. Document Types
- From the left navigation pane, go to Modules > Page Process.
The Plugin Configuration screen displays.
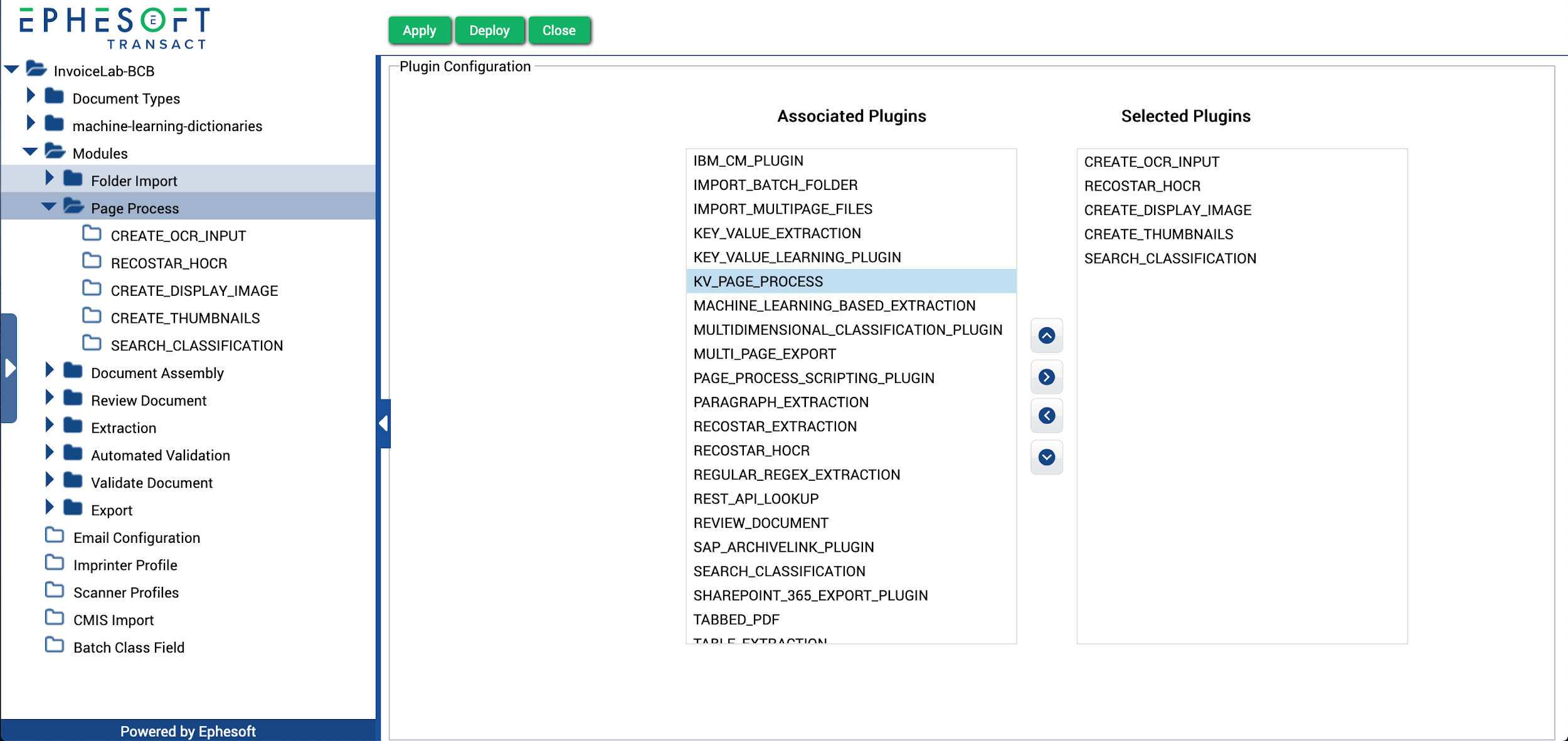
Figure 2. Page Process Module
- Select the KV_PAGE_PROCESS plugin from the Associated Plugins column.
- Move the KV_PAGE_PROCESS plugin to the Selected Plugins column. Make sure the plugin is towards the bottom of the list, after the CREATE_OCR_INPUT and RECOSTAR_OCR plugins.
Some plugins have dependencies on other plugins. In this case, you may get the following message.
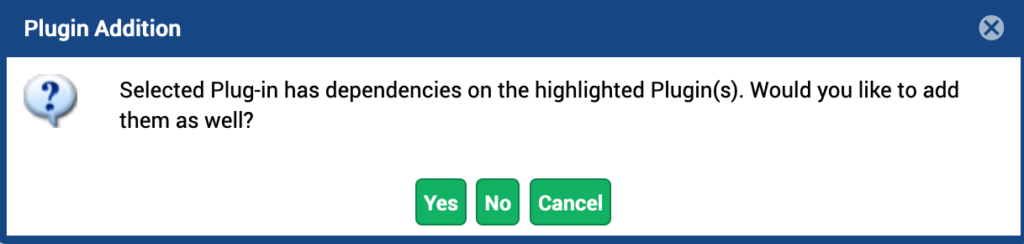
Figure 3. Plugin Dependencies
Click YES to add the selected plugin along with the dependencies. Click NO to add the selected plugin without the dependencies. Click CANCEL to cancel the operation.
Note: There is currently a known issue with CHE being incorrectly marked as dependent. Please refer to CHE Plugin Incorrectly Marked as Dependent for more information.
- Determine what method you want Transact to use for classification.
- Only use the KV_PAGE_PROCESS plugin:
- Remove the SEARCH_CLASSIFICATION plugin from the Page Process module.
- Configure the DOCUMENT_ASSEMBLER plugin to use KeywordClassification as the DA Classification Type. Refer to Document Assembler Plugin for help.
- With this configuration, Transact will only use keyword classification for classification.
- Automatic classification based on all configured classification methods:
- Keep the SEARCH_CLASSIFICATION plugin in the Page Process module.
- Configure the DOCUMENT_ASSEMBLER plugin to use AutomaticClassification as the DA Classification Type. Refer to Document Assembler Plugin for help.
- With this configuration, Transact will use all configured classification methods and then choose the result with the highest confidence score.
- Click Deploy.
- Go to Modules > Page Process > KV_PAGE_PROCESS.
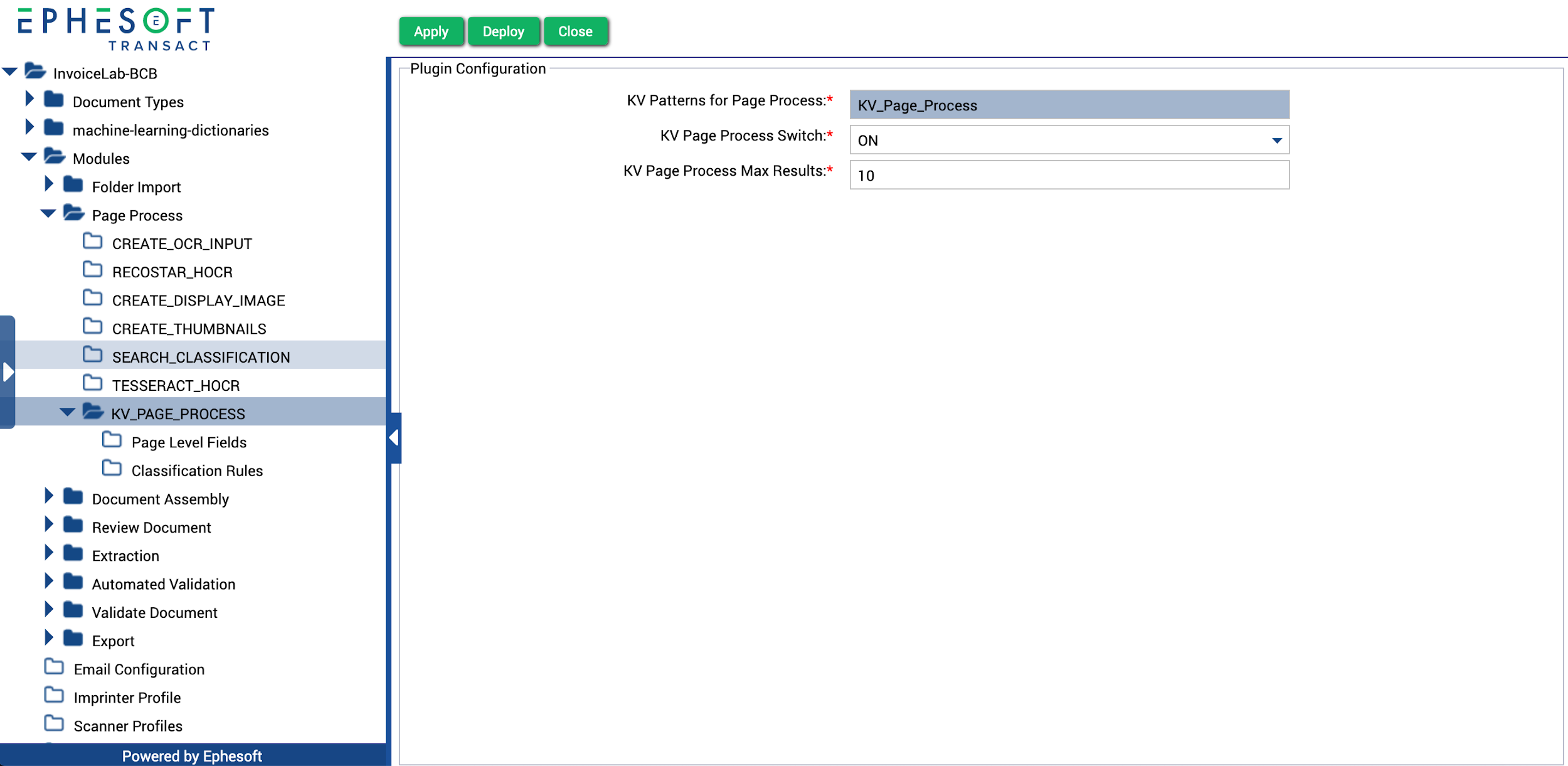
Figure 4. KV_PAGE_PROCESS Plugin
- Set the KV Page Process Switch to ON.
- If desired, configure the KV Page Process Max Results.
- Click Deploy.
Create Page-Level Fields
The Key-Value Page Process plugin can be used for document classification and separation by executing named key-value extraction rules during the Page Process step of the workflow. Transact extracts these values and stores them as page-level fields. Page-level fields help you build classification rules. We will address classification rules in a later section.
The next stage of the process involves defining which values we will be pulling from the document. To do so, we need to specify values in our page-level fields. To do so, see the steps below.
- Go to Modules > Page Process > KV_PAGE_PROCESS > Page Level Fields.
- Click Add.
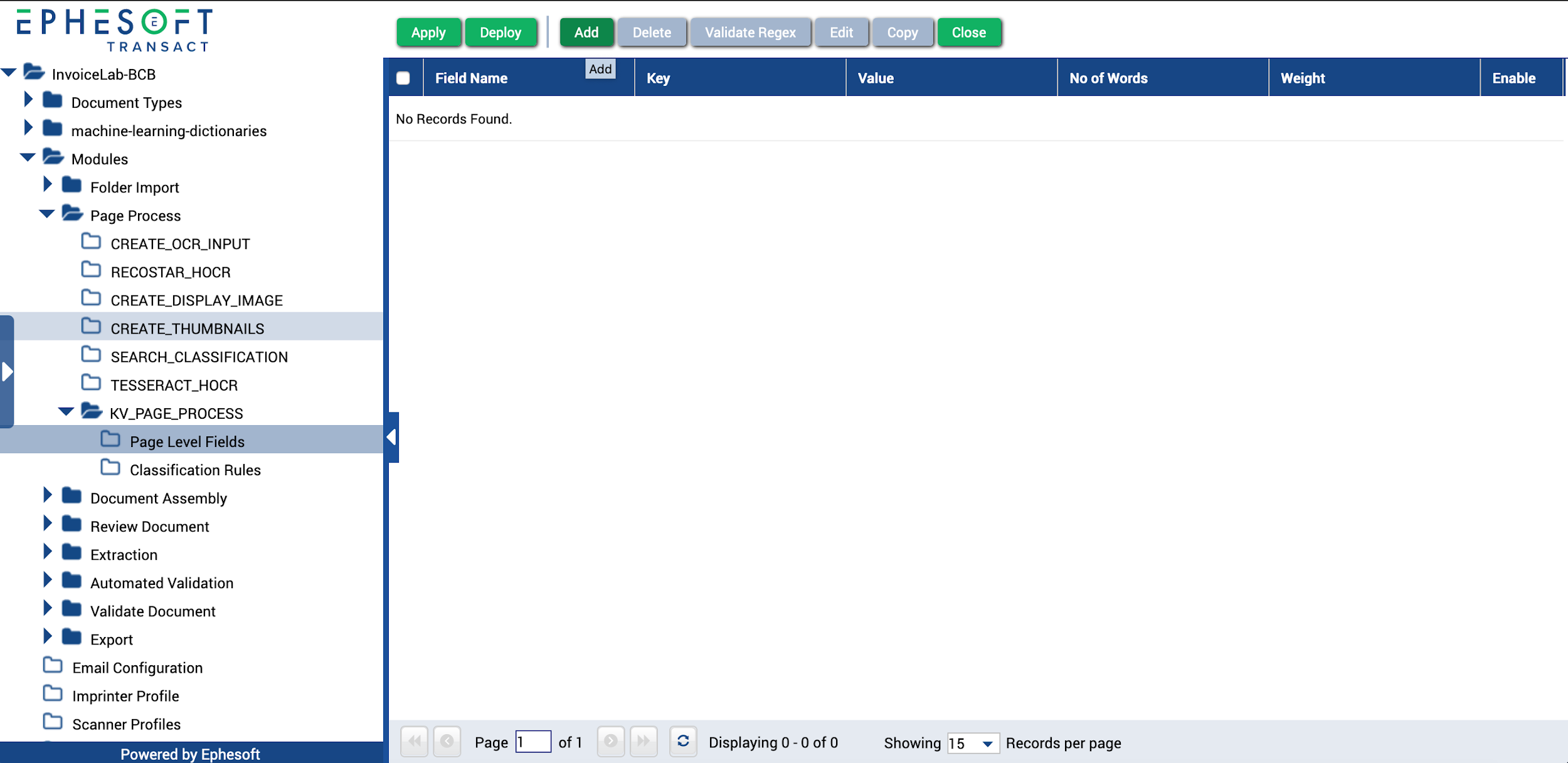
Figure 5. KV_PAGE_PROCESS Plugin Page-Level Fields
The following screen displays.
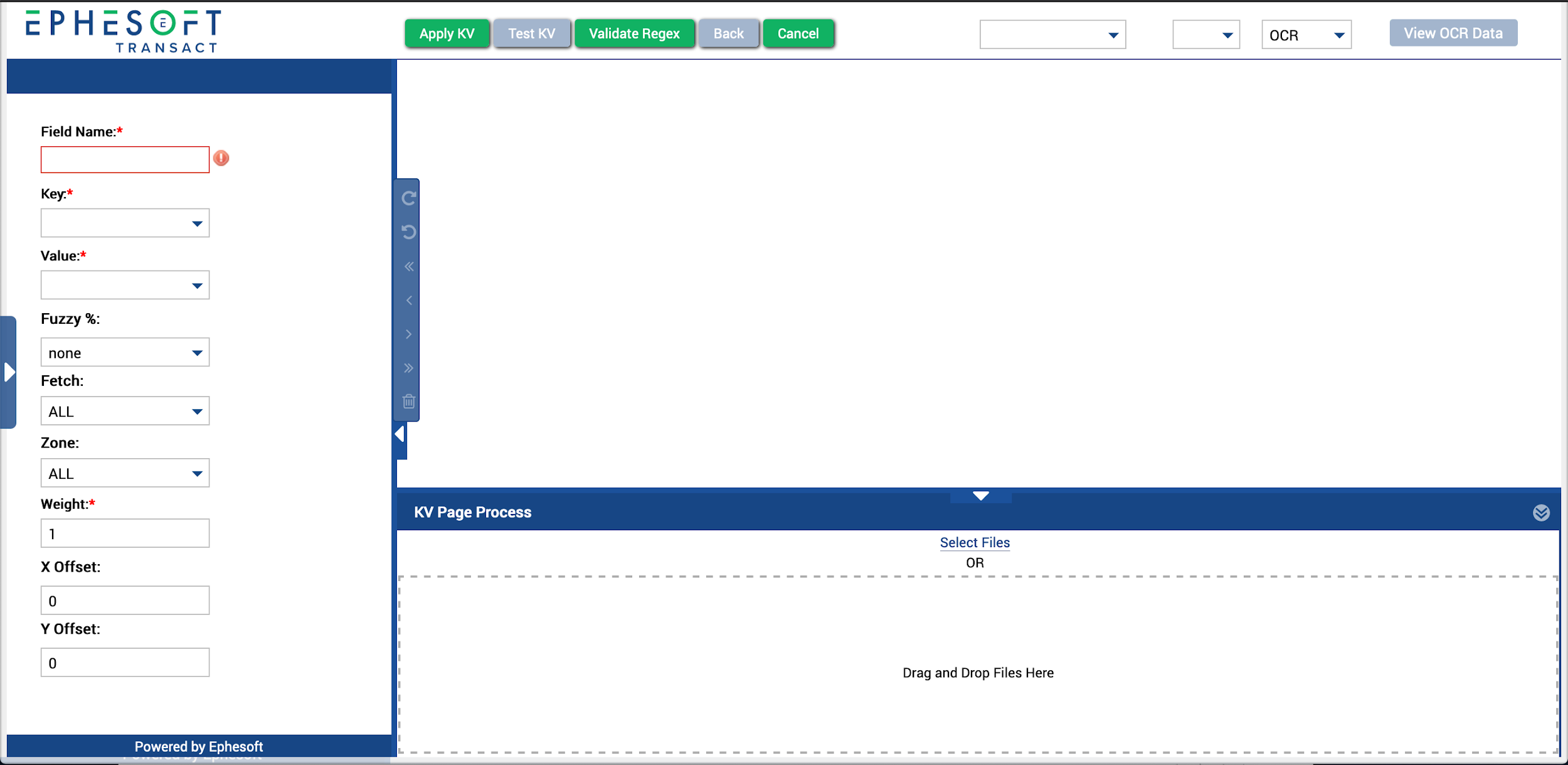
Figure 6. Creating a Page-Level Field
- Click Select Files or drag and drop files into the KV Page Process panel.
Note: Supported file types are PDF and TIF.
The image view pane will display the KV Page Process rule builder, shown below.
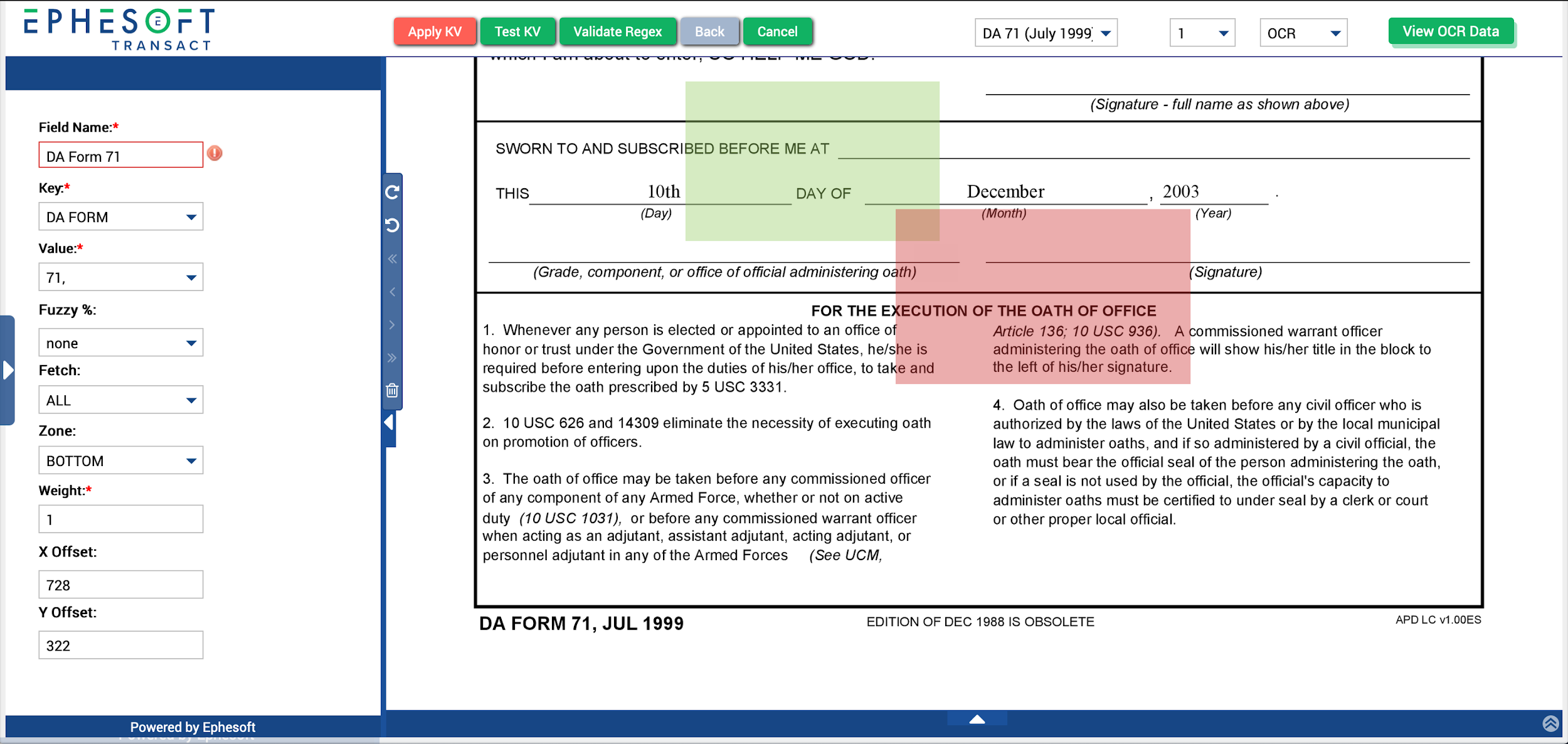
Figure 7. Resizing the Key and Value Fields pt. 1
- Enter a unique value in the Field Name box. This name will be used to identify this field in the subsequent Classification Rules section, so use something descriptive. If the KV field will only be used to identify a single form, like the DA 71 example above, you can name this field something like “DA Form 71”. If the KV field will be used to identify a variety of different forms, you can name this field something like “DA Form Number”.
- Drag and resize the key overlay (green) to the text or label that will serve as the key.

Figure 8. Resizing the Key and Value Fields pt. 2
- Click the key overlay to open the Suggest Regex window. This will display the text captured inside the overlay.
- Select your chosen regex and click OK. This regex will be added to the Key field in the left column.
- Repeat steps 5-7 for the value overlay (red).
- Enter the relevant configuration details as described in the table below:
| Configurable Property | Options | Description |
| Fuzzy % |
|
This parameter specifies if the key will still be identified even if there is not an exact match to the key regex pattern.
Important: If you select a fuzzy percentage, you will not be able to use a regex for the Key pattern. If you select both a fuzzy percentage and key regex, you will not receive any results during extraction. |
| Fetch |
|
This parameter specifies how many instances of the value should be extracted from the value zone.
For example, if ALL is selected, all characters from the value zone will be extracted. If FIRST is selected, only the first matching pattern from the value zone will be extracted. |
| Zone* |
|
This parameter specifies on which section of the document to perform key-value extraction.
For example, if ALL is selected, key-value extraction will be performed on the entire page. If TOP is selected, it will only be performed on the top section of the page. |
| Weight | 0-1 | This parameter is a configurable value (0-1) that is multiplied by the confidence score to calculate a new confidence score. This is to allow an extraction rule to be prioritized over another within the same index field. |
| X Offset | N/A | The application will set this value based on the placement and size of the key and value overlays. |
| Y Offset | N/A | The application will set this value based on the placement and size of the key and value overlays. |
* Extraction is not limited to the exact positions of the key and value defined in the extraction rule. Ephesoft Transact will search the specified fetch, page, and zone for the key pattern and return results if it finds the matching value pattern. This allows Ephesoft Transact to extract data from structured, semi-structured, and unstructured documents.
- Click Test KV.
The extraction results are displayed in the KV Page Process grid as shown in the image below.
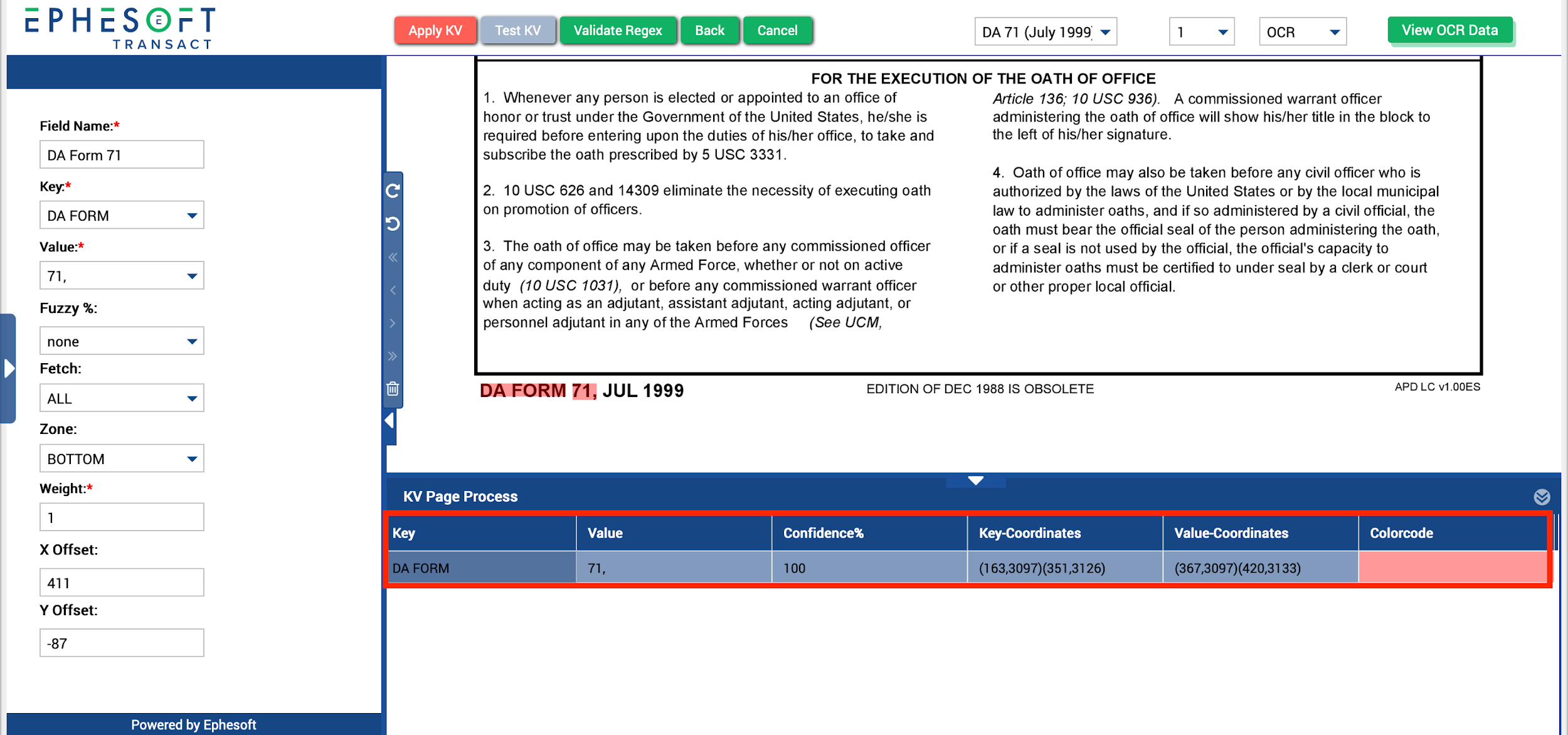
Figure 9. KV Page Process Extraction Results
- Click Apply KV to save the rule.
The updated Page Level Fields screen displays.
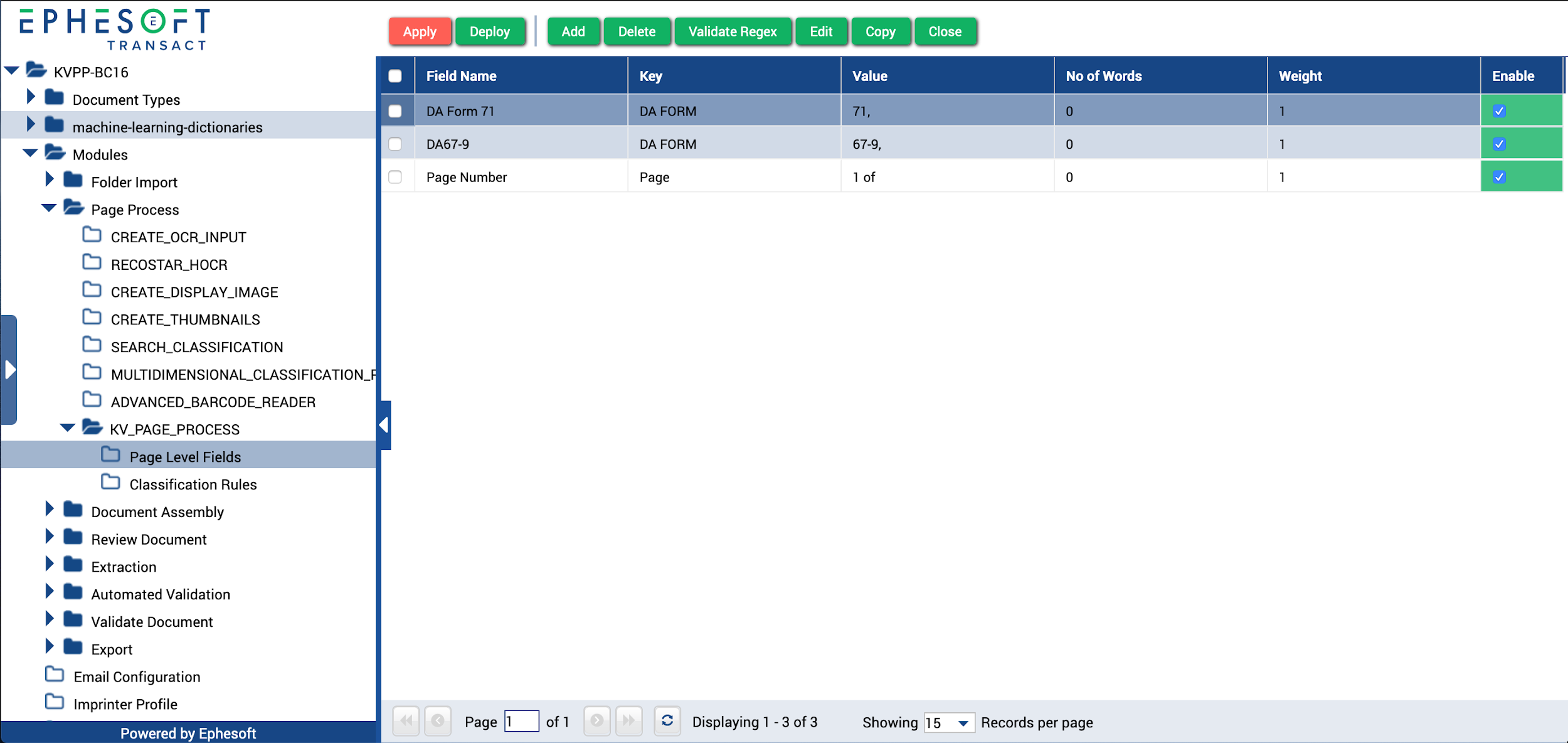
Figure 10. Completed Page-Level Fields
- Click Apply.
Follow the process described above to add multiple page-level fields.
Create Classification Rules
This stage of the process involves creating classification rules. Classification rules use page-level fields to determine classification and separation. It essentially gives “if/then” instructions to Transact, clarifying how it should treat certain documents based on the associated page-level fields. Now that the page-level fields are established, classification rules can be added.
- Go to Modules > Page Process > KV_PAGE_PROCESS > Classification Rules.
The following screen displays.
Figure 11. KV_PAGE_PROCESS Plugin Classification Rules Page
- Click Add.
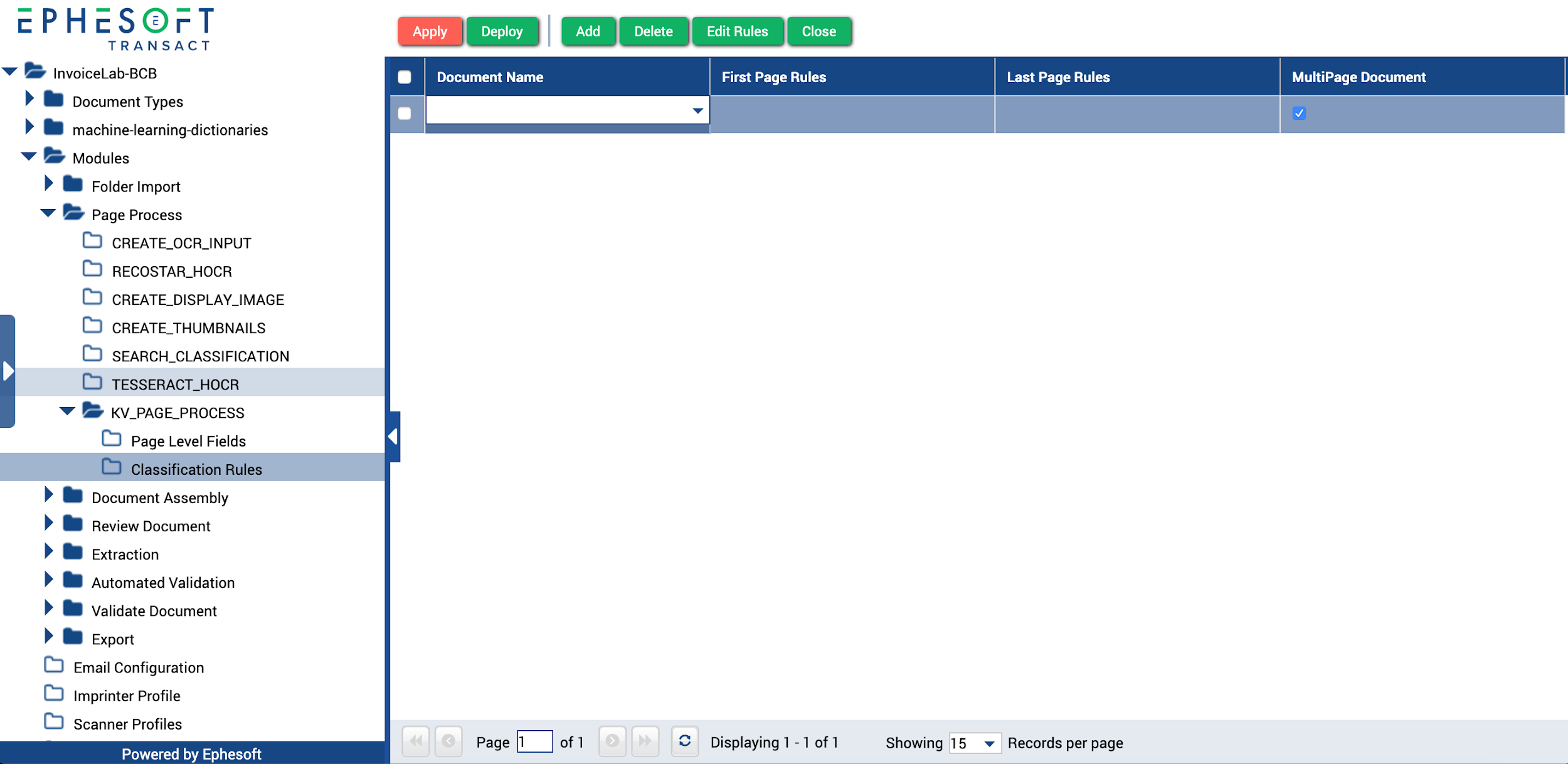
Figure 12. Adding Classification Rules
- Select an existing document type from the Document Type Name drop-down list. When the rules are executed, if this rule is successful, the document will be set to this document type.
Note: The Multipage Document checkbox is selected by default. Deselect it for single-page document types.
- Configure the remaining fields according to your workflow needs.
The following fields are available in the grid on the Classification Rules page of the KV_PAGE_PROCESS plugin.
| Column Name | Description |
| Document Name | Document type for which the rule expression will be configured. |
| First Page Rules | Rules set to identify the first page of the document. Multiple rules for the first page will be combined using an OR operation. |
| Last Page Rules | Rules set to identify the last page of the document. Multiple rules for the last page will be combined using an OR operation. |
| MultiPage Document | Select this checkbox if documents of this document type have multiple pages. When working with single-page documents, Transact only needs to identify the document type. When document types can have multiple pages, Transact needs to understand how to determine where a document ends. |
- Click Edit Rules.
The following screen displays.
Figure 13. Classification Rules Builder
- Click Add.
The Add Rule Expression dialog box displays.
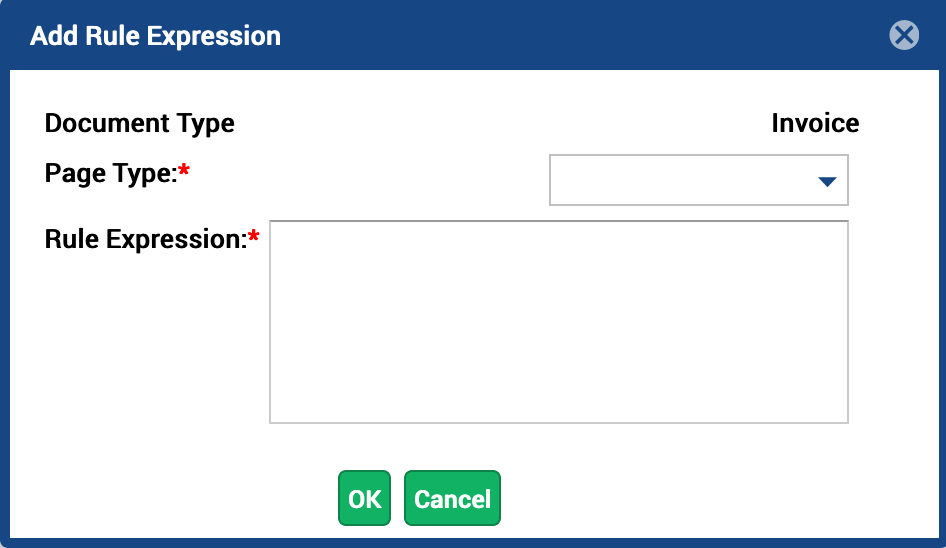
Figure 14. Adding Rule Expressions
- Select page type from the Page Type drop-down list. The available options are First Page and Last Page.
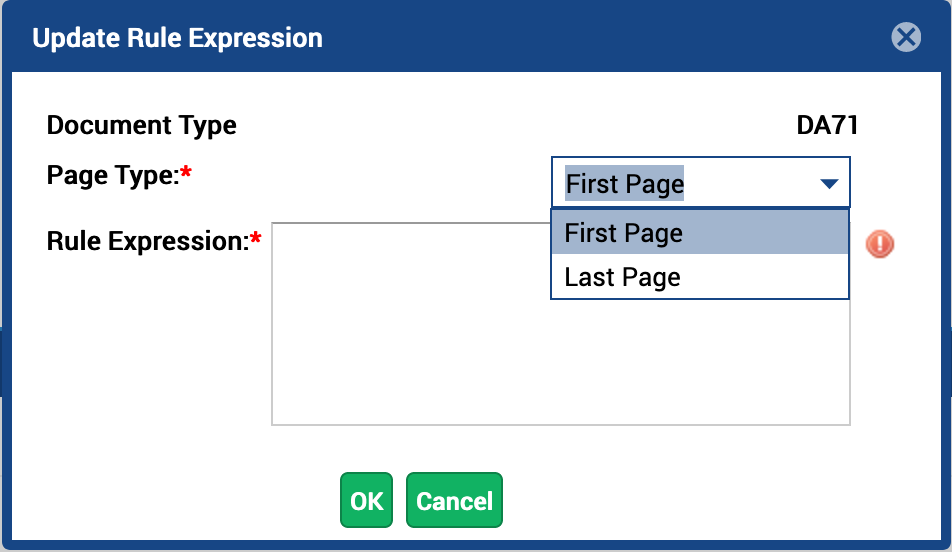
Figure 15. Updating Page Type in the Rule Expression Dialog Box
- Enter the desired rule expression using the auto-suggestions dropdown menu.
Rule expressions can be any valid logical expression that can be resolved to a true or false value. This helps to determine the type of document being processed.
Refer to the appendix at the end of this document for a list of rule expression options.
See the next section for more details about rule expressions and operators.
Rule Expressions
Rule expressions can be any valid logical expression that can be resolved to a true or false value. This helps to determine the type of document being processed.
A rule expression can be in the form of <Page Level Field> <Operator> <Value>
- Page Level Field is the Field Name, defined in ‘Page Level Fields’. It will be auto-suggested to users.
- Operator can be any valid operation from the suggestions dropdown.
- Value can be any combination of characters enclosed within single quotes.
- When multiple rule expressions are combined with AND or OR, individual expressions must be surrounded by parentheses.
- Click inside the Rule Expression textbox and select your desired page-level field from the dropdown list. Page-level fields will appear at the top of the dropdown list.
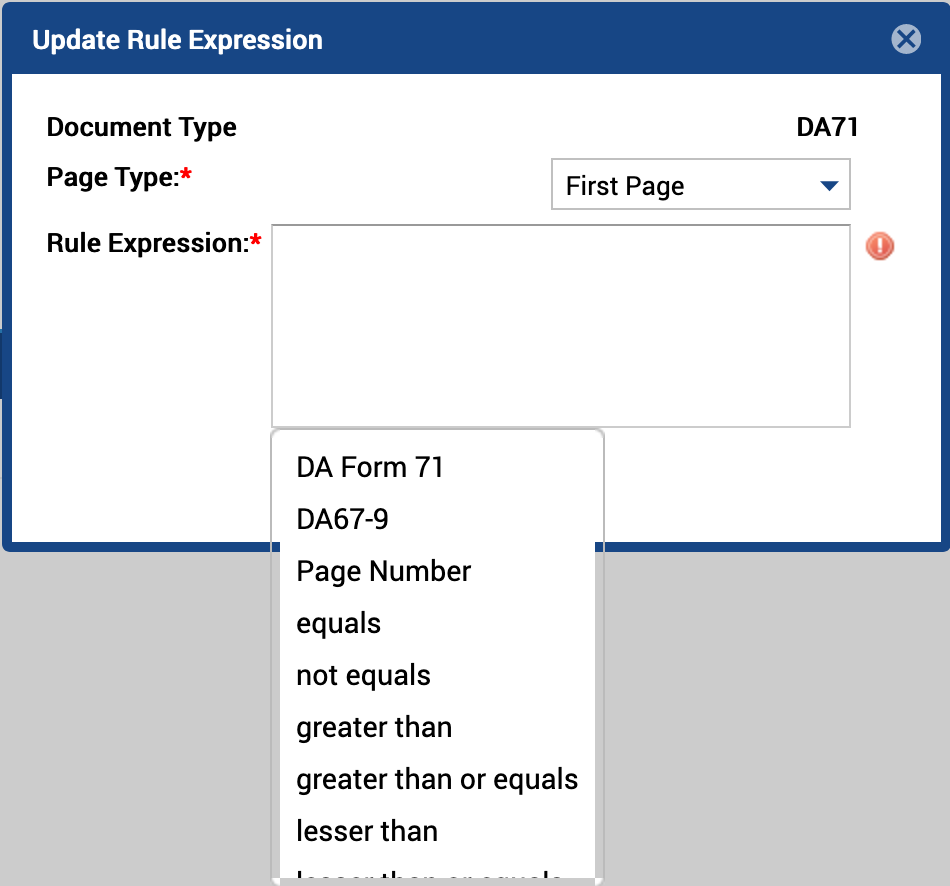
Figure 16. Specifying Document Types in the Rule Expression Dialog Box
- Add a space after the page-level field. The dropdown menu reappears.
- Select any valid operation from the Rule Expression dropdown menu.
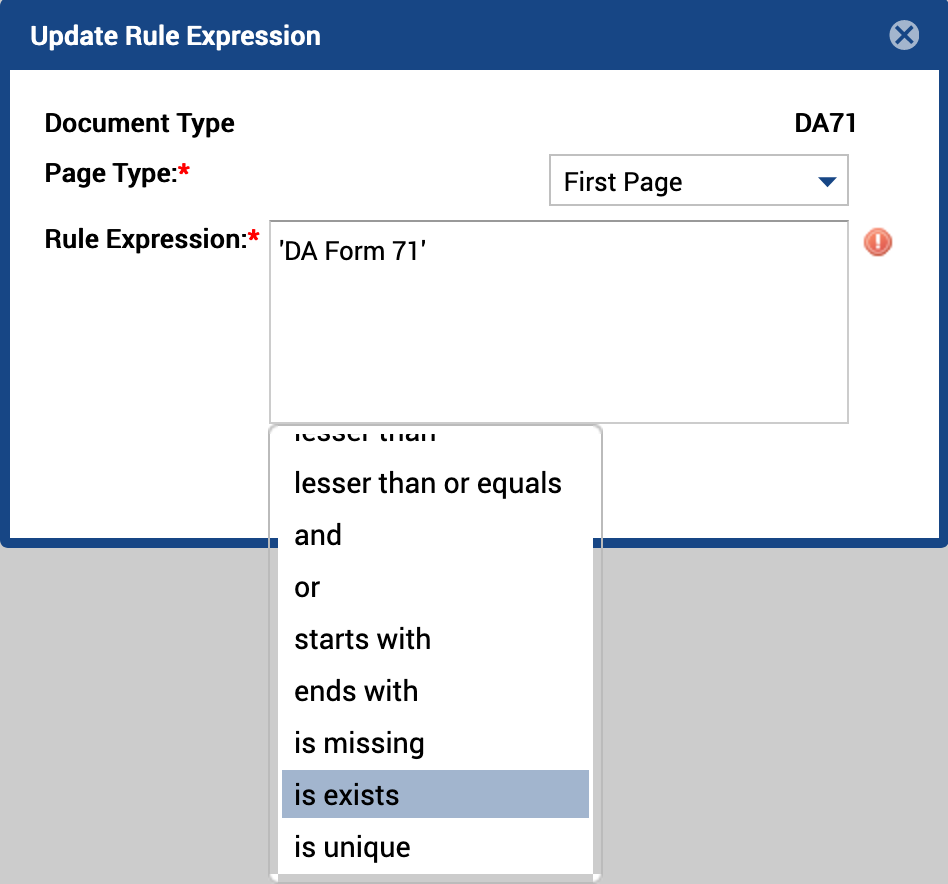
Figure 17. Building a Rule Expression
- Add more operations as needed to complete your expression.
Note: Many list items will change after you select them. For example, page-level fields will automatically be surrounded by single-quotes, and the operators “and” and “or” will be replaced with “&&” and “||” respectively.
Please see below for examples of valid, complete rule expressions and their usages.
| Rule Expression | Usage |
| ‘DA Form 71’ is exists | When used as a first page rule for classification, if the DA Form 71 field is found, then the document type will be set to DA Form 71. |
| (‘Form1234’ is exists) && (‘Form1234Page1’ is exists) | When used as a first page rule for classification of multipage documents, if the “Form1234” page-level field is found, and the “Form1234Page1” page-level field is found, this page is determined to be the first page of the document. |
| (‘Form1234’ is exists) && (‘Form1234Page2’ is exists) | When used as a last page rule for classification of multipage documents, if the “Form1234” page-level field is found, and the “Form1234Page2” page-level field is found, this page is determined to be the last page of the document. |
| (‘Invoice No’ is unique) && (‘Company’ is exists) | When used as a first page rule for classification, if the invoice number is unique and the company name is on the document, then this page is determined to be the first page of a new invoice. |
- Once you’ve completed your rule expression click OK.
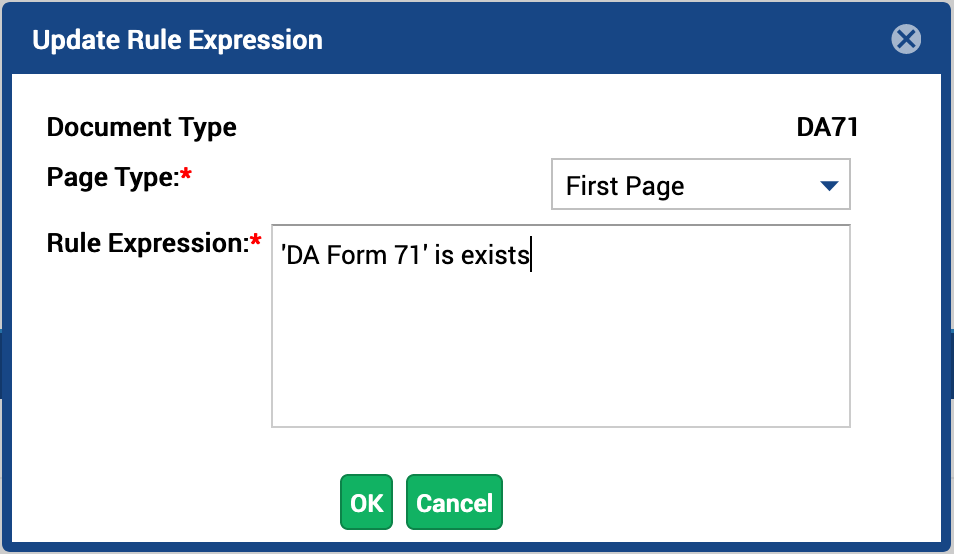
Figure 18. A Complete Rule Expression
- Click Apply.
The following screen displays.
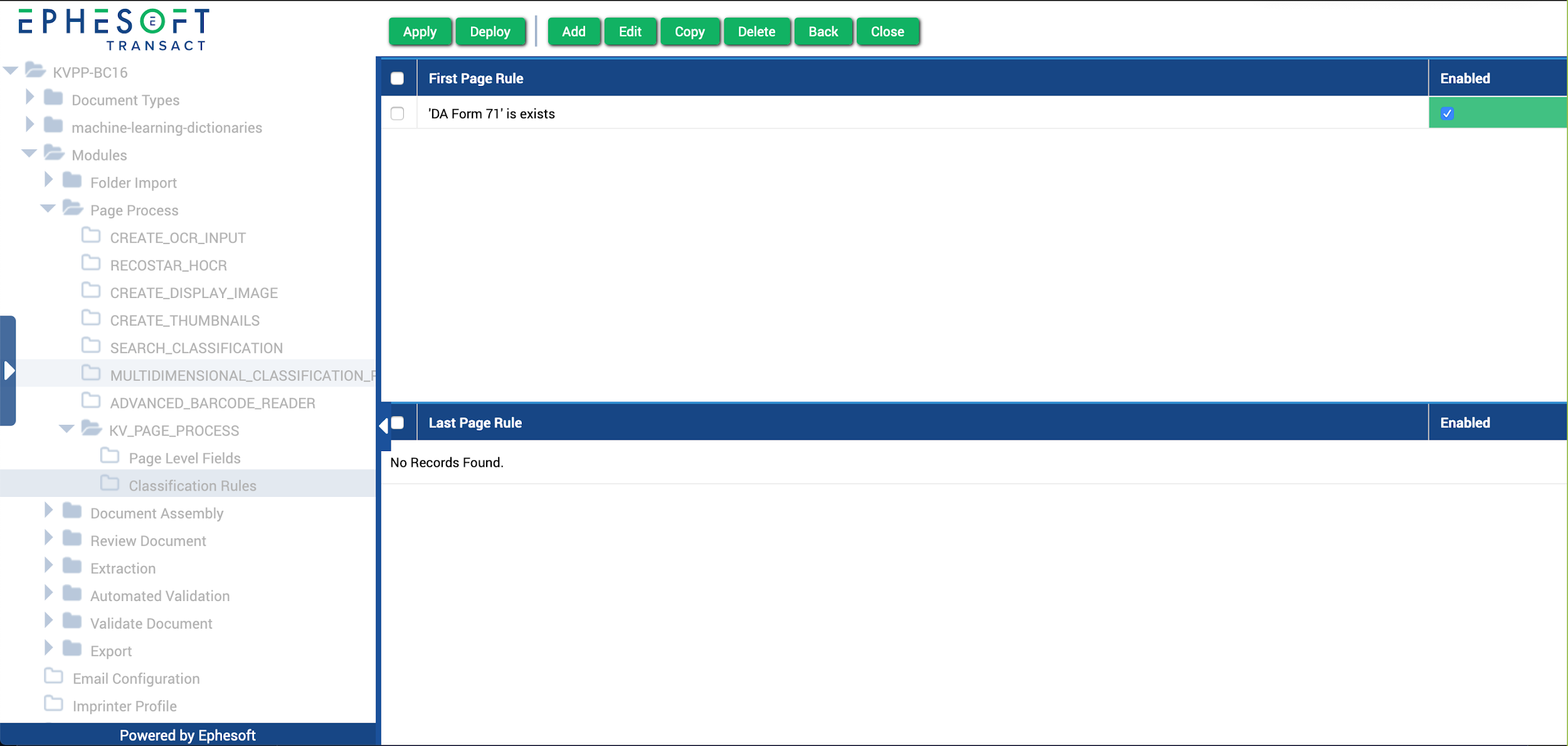
Figure 19. First and Last Page Classification Rules Interface
- Click Back.
The following screen displays.
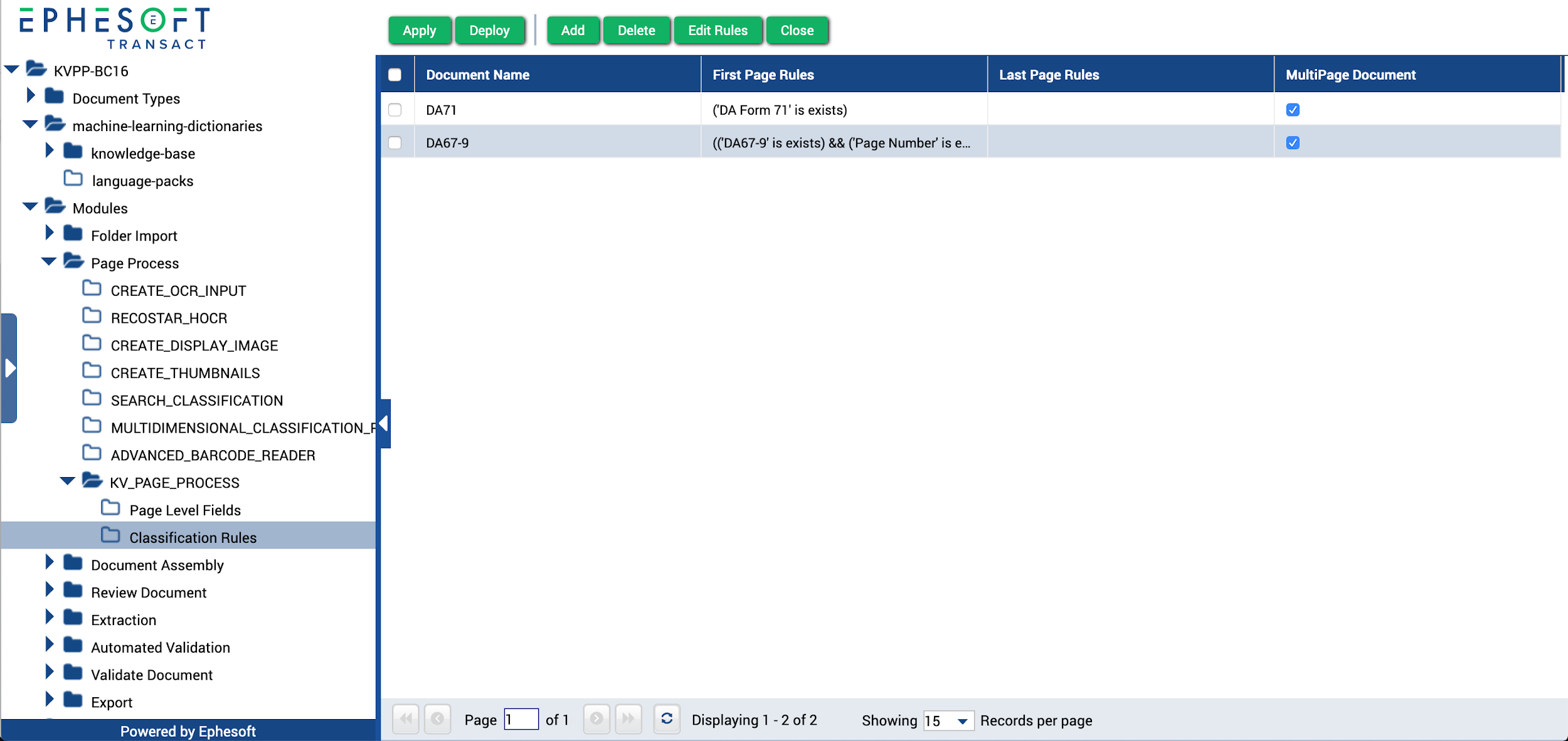
Figure 20. Active Classification Rules
- Click Apply.
Note: Page-level fields and classification rules defined for keyword classification are associated with individual document types. Therefore, if the user deletes a document type, all page-level fields and classification rules associated with that document type will be automatically deleted as well.
Document Assembly using Keyword Classification
For more information about the keyword classification workflow, please refer to Document Assembler Plugin.
Conclusion
You have successfully configured the keyword classification using the KV_PAGE_PROCESS plugin in Ephesoft Transact.
Appendix
Below is a list of operations that can be combined to create rule expressions.
Note: The Operation Name column is the user-friendly version of the Operator column. When building the rule expression using the rule expression dropdown menu, the user picks from a list of operation names to build the rule. Once the rule applies, it changes to match the format in the Operator column.
| Operation Name | Operator | Example | Value Type | Description |
| equals | == | ‘Invoice No’ == 1234 |
|
Returns true if the page-level field exactly matches the value. |
| not equals | != | ‘Invoice No’ != ‘abc’ |
|
Returns true if the page-level field doesn’t match the value. |
| greater than | > | ‘Invoice No’ > ‘2011-12-31’ |
|
Returns true if the page-level field is greater than the value. |
| greater than or equals | >= | ‘Invoice Date’ >= ‘2011-01-01’ |
|
Returns true if the page-level field is greater than or equal to the value. |
| lesser than | < | ‘Invoice No’ < 1234 |
|
Returns true if the page-level field is less than the value. |
| lesser than or equals | <= | ‘Invoice No’ <= 1234 |
|
Returns true if the page-level field is less than or equal to the value. |
| and | && | (‘Form1234’ is exists) && (‘Form1234Page1’ is exists) |
|
Used to combine expressions. Any time ‘and’ is used, each expression must be in parentheses. Both operations must return true values for the overall operation to be considered true. |
| or | || | (‘Invoice Num’ is unique) || (‘Page1’ is exists’) |
|
Used for logical combinations of expressions. Any time ‘or’ is used, each expression must be in parentheses. If either operation results in a true value, the overall operation will be considered true. |
| starts with | =^ | ‘Invoice No’ =^ ‘INV’ |
|
Returns true if the page-level field is found to begin with this string. |
| ends with | =$ | ‘Company’ =$ ‘Ltd.’ |
|
Returns true if the page-level field is found to end with this string. |
| is missing | is missing | ‘Invoice No’ is missing |
|
True if the page-level field is not found. |
| is exists | is exists | ‘Invoice No’ is exists |
|
True if the page-level field is found. |
| is unique | is unique | ‘Invoice No’ is unique |
|
True for the first occurrence of the page-level field in the uploaded batch, then false for all occurrences.
For example, if multiple bank statements are submitted to Transact at the same time, but each monthly statement has a different Statement Date field, the ‘is unique’ operator will return true for each page where a new statement date is found. |