Available: on-premises, cloud
Overview
The DOCUMENT_ASSEMBLER plugin is responsible for forming multi-page documents from single pages. This plugin reads all the pages present inside the “Unknown” document type and creates new documents on the basis of page-level fields. The DOCUMENT_ASSEMBLER plugin will review page level field results and use the page_level_index fields to determine the document type, as well as which page is the first page.
Ephesoft Transact supports 7 types of classification, which are explained in further detail below.
- Barcode classification: Ephesoft Transact forms documents based on a barcode being present in the processing images. The value of the barcode present is extracted in the Page Process module and used to assign the type of page. If a barcode is extracted, that page is set as the starting page of the new document. If a barcode is not extracted, the page is added to the existing documents.
- Search classification (Lucene): Ephesoft Transact forms documents based on text found on the images. While learning images in document types, indexes for the text in input files are created and stored. These indexes are matched with the text in processed images to classify the images into document types. Text on newly processed images is matched against the text on learned images to classify documents.
- Image classification: Ephesoft Transact forms documents based on learned image samples. Image Classification is done by superimposing the thumbnails of the learned images and the images being processed to generate the confidence of the two images matching. The images are classified into document types based on the confidence score.
- Automatic classification: Ephesoft Transact forms documents based on the top results from the page level fields populated by all classification types. Barcode classification takes first priority, followed by Keyword classification. The remaining classification types have equal priority.
- One Document classification: Ephesoft Transact forms only one document and all pages are classified into that document. If multiple documents are configured in the Batch Class then all input images are classified into the first document type.
- Keyword-based classification: This classification type is used to classify documents based on the presence of keywords in the document types and is controlled by the KV_PAGE_PROCESS plugin. You can configure KV_PAGE_PROCESS plugin from the Page Process module for each document type. Refer to KV Page Process Plugin for more information.
- Multidimensional classification: This classification mechanism is used to classify the documents across various dimensions and then combine the score of each dimension to give better accuracy and confidence. For more information, refer to Multidimensional Classification.
Only one type of classification can be set at a time for a batch. However, if the classification type is set to Automatic then the results of several classification types (Barcode, Image, Lucene, Keyword, and Multidimensional) are all taken into consideration, and the top results among them are used to classify pages into documents.
Document Assembler Plugin Properties
1. DA Merge Unknown Document Switch
This feature is used to merge the UNKNOWN document types into a classified document.
Example: Suppose after the algorithm the documents are classified as listed below:
- DOC1 – UNKNOWN
- DOC2 – UNKNOWN
- DOC3 – DOC_TYPE_1
- DOC4 – UNKNOWN
- DOC5 – UNKNOWN
- DOC6 – DOC_TYEP_2
- DOC7 – UNKNOWN
- DOC8 – DOC_TYPE_2
After executing the DA Merge Unknown Document Switch, the results would be:
- DOC1 – UNKNOWN
- DOC2 – UNKNOWN
- DOC3 – DOC_TYPE_1
- DOC4 – DOC_TYPE_2
- DOC5 – DOC_TYPE_2
DOC4 and DOC5 were merged into DOC3, and DOC7 was merged into DOC6.
2. Predefined Document Change
This feature is used to set a particular document type for any documents whose confidence value is less than the configured threshold values. The UNKNOWN document types will not be affected.
Example: Suppose after the algorithm the documents are classified with provided confidence values. The threshold value is 50 and the document type to be set is DOC_TYPE_DEFAULT:
- DOC1 – DOC_TYPE_1 : 40
- DOC2 – UNKNOWN : 0
- DOC3 – DOC_TYPE_1 : 30
- DOC4 – DOC_TYPE_4 : 70
- DOC6 – DOC_TYPE_DEFAULT : 85
- DOC7 – DOC_TYPE_DEFAULT : 30
After executing the Predefined Document Change, the resulting classification would be:
- DOC1 – DOC_TYPE_DEFAULT
- DOC2 – UNKNOWN
- DOC3 – DOC_TYPE_DEFAULT
- DOC4 – DOC_TYPE_4
- DOC6 – DOC_TYPE_DEFAULT
- DOC7 – DOC_TYPE_DEFAULT
Any documents below the configured confidence threshold of 50 were set to DOC_TYPE_DEFAULT.
3. Change Unknown Document Type
This feature is used to set a particular document type to all the UNKNOWN document types. You can provide the document type for each batch class in the DOCUMENT_ASSEMBLER plugin under Modules. All UNKNOWN document types will be classified as the provided document type.
Example: Suppose after the algorithm the documents are classified as listed below:
- DOC1 – UNKNOWN
- DOC2 – UNKNOWN
- DOC3 – DOC_TYPE_1
- DOC4 – UNKNOWN
- DOC5 – UNKNOWN
- DOC6 – DOC_TYPE_2
- DOC7 – UNKNOWN
- DOC8 – DOC_TYPE_2
After setting the Change Unkown Document Type to DOC_TYPE_DEFAULT then the classification is as follows:
- DOC1 – DOC_TYPE_DEFAULT
- DOC2 – DOC_TYPE_DEFAULT
- DOC3 – DOC_TYPE_1
- DOC4 – DOC_TYPE_DEFAULT
- DOC5 – DOC_TYPE_DEFAULT
- DOC6 – DOC_TYPE_2
- DOC7 – DOC_TYPE_DEFAULT
- DOC8 – DOC_TYPE_2
Document types previously listed as UNKNOWN are now classified as DOC_TYPE_DEFAULT.
4. DA Delete Document First Page
This feature is used to delete the first page of all the classified documents. This is used to remove the separator sheets or barcode pages if there are any in the batch. If the DA Delete Document First Page switch is ON then the first page of all the documents will be removed. No pages will be removed if the document is only one page.
5. Regex Classification
When performing classification using Barcode Classification or from the results of the KV_PAGE_PROCESS plugin, then Ephesoft Transact will check all page level field values with the regular expression (regex) for the UNKNOWN document type. For the page whose page level field has a value matching to regular expression, the DOCUMENT_ASSEMBLER plugin will create a new document with the same type as the one provided in Default Regex Document Type property. This way the DOCUMENT_ASSEMBLER plugin will create a new document for each page which has similar value to the regex provided.
Example:
- Regex: a*
- Default document type: Regex Doc Type
Documents are classified as listed below before execution of this feature:
- DOC1 – type: Doc Type 1
- DOC2 – type: Doc Type 2
- DOC3 – type: UNKNOWN
- DOC4 – type: Doc Type 1
In this scenario, the DOCUMENT_ASSEMBLER plugin will only work on DOC3 as this is the only UNKNOWN document type.
Let’s assume documents DOC1 and DOC2 has pages PG0, PG1 and PG2 among them and DOC3 has four pages with the following page level field values:
| Page | Page level field values |
| PG3 | i. 123ii. Invoiceiii. US |
| PG4 | i. 990ii. Invoiceiii. Checklist |
| PG5 | i. 789ii. Documentiii. Aaa |
| PG6 | i. 456ii. Applicationiii. Checklist |
As none of the pages have a page level field that matches the provided regex ( a* ), these pages will remain in DOC3 as UNKNOWN.
In PG5, the third page level field (Aaa) matches the regex, so this page will be put into a new document (DOC4) with the configured default document type: Regex Doc Type.
In PG6, the second page level field (Application) also matches the regex, so this page will also be put into a new document (DOC5) with the configured default document type: Regext Doc Type.
The final classified documents will be:
- DOC1 – type: Doc Type 1
- DOC2 – type: Doc Type 2
- DOC3 – type: UNKNOWN (pages: PG3, PG4)
- DOC4 – type: Regex Doc Type (pages: PG5)
- DOC5 – type: Regex Doc Type (pages: PG6)
- DOC6 – type: Doc Type 1
6. Advanced Document Assembler Algorithm
- First Page: When the Advanced Document Assembler algorithm encounters the FIRST_PAGE then the algorithm will create a new document and add this page to that document. For other pages that algorithm encounters, it will check their page type and it will merge them if it finds matching alternate values.
Scenario 1:
If the algorithm has three pages as input and they all are classified as follows:
- A_FIRST_PAGE
- A_FIRST_PAGE
- A_FIRST_PAGE
Three individual documents are created.
Scenario 2:
If the algorithm has three pages as input and they are classified as follows:
- A_FIRST_PAGE
- B_FIRST_PAGE
- C_FIRST_PAGE
- When the algorithm encounters the A_FIRST_PAGE, it will make a new document type.
- For B_FIRST_PAGE, the algorithm will check the alternate values for A_MIDDLE_PAGE and A_LAST_PAGE in page B_FIRST_PAGE. Whichever value is higher, the algorithm will choose that page. If the confidence for it is comparable to the confidence threshold of the respective page type then two pages will be merged. Otherwise, the first document will be closed and a new document will be created.
- For C_FIRST_PAGE the same scenario is followed.
- If the confidence of the current page classified as X_FIRST_PAGE is more than or equal to the First Page Confidence Threshold (F_P_C_T) then a new document will be created and the current page will be added to the document.
- Last Page: When the Advanced Document Assembler algorithm encounters the LAST_PAGE, the algorithm will merge them if the confidence threshold matching algorithm is successful for a merge.
Scenario 1:
If the algorithm has three pages as input and they all are classified as follows:
- A_LAST_PAGE
- A_LAST_PAGE
- A_LAST_PAGE
- Suppose there are no open documents present. When the algorithm encounters the first A_LAST_PAGE, it will put the page in the new document.
- The second and third pages have the same type (A_LAST_PAGE) so the algorithm will merge this page in the open document type and close the document.
Scenario 2:
If the algorithm has three pages as input and they all are classified as follows:
- A_LAST_PAGE
- B_LAST_PAGE
- C_LAST_PAGE
- The first page will be put in a new document.
- The next page is picked up which is B_LAST_PAGE. The two pages have different types so the algorithm will look into the top five alternate values for this page and calculate the confidence for A_LAST_PAGE (since the document already has A_LAST_PAGE, the algorithm will not consider the middle page confidence).
- If the algorithm is positive for merge then the two pages will be merged into one document.
- If the algorithm is negative for merge then the first document will be closed and a new document will be created with B_LAST_PAGE placed in it.
- C_LAST_PAGE will follow the same procedure as B_LAST_PAGE.
- Middle Page: When the Advanced Document Assembler encounters a middle page, it will perform the same procedure for merging the pages in the same document. But from alternate values algorithm will consider both middle pages and last pages for higher confidence until a last page is added to the open document.
- The scenario for merging follows the same process as the last page.
7. Confidence Threshold Matching Algorithm
The Confidence Threshold Matching Algorithm decides if the pages must be merged.
Consider the confidence of a page as “X” and the page the algorithm is trying to match is a middle page with confidence “Y”, then the algorithm will check if
(X-Y) < M_P_C_T
Then the algorithm will merge the pages into one document. If the confidence threshold is not met, the pages will not merge and a new document will be created with this page in it.
When the algorithm is matching the last pages and the confidence of the last page from alternate values is “Y”, then the algorithm will check if
(X-Y) < L_P_C_T
If this is true, then the algorithm will merge them. If the confidence threshold is not met, the pages will not merge.
Assumptions
There are following assumptions and requirements for this algorithm:
- For alternate values, the algorithm will only consider the top 5 alternate values.
- The algorithm will have three confidence thresholds as page types have different weights:
- First_Page_Confidence_Threshold (F_P_C_T)
- Middle_Page_Confidence_Threshold (M_P_C_T)
- Last_Page_Confidence_Threshold (L_P_C_T)
UI Configuration
The DOCUMENT_ASSEMBLER plugin can be configured in the Plugin Configuration screen. Open the batch class you want to configure and select Modules > Document Assembly > DOCUMENT_ASSEMBLER.
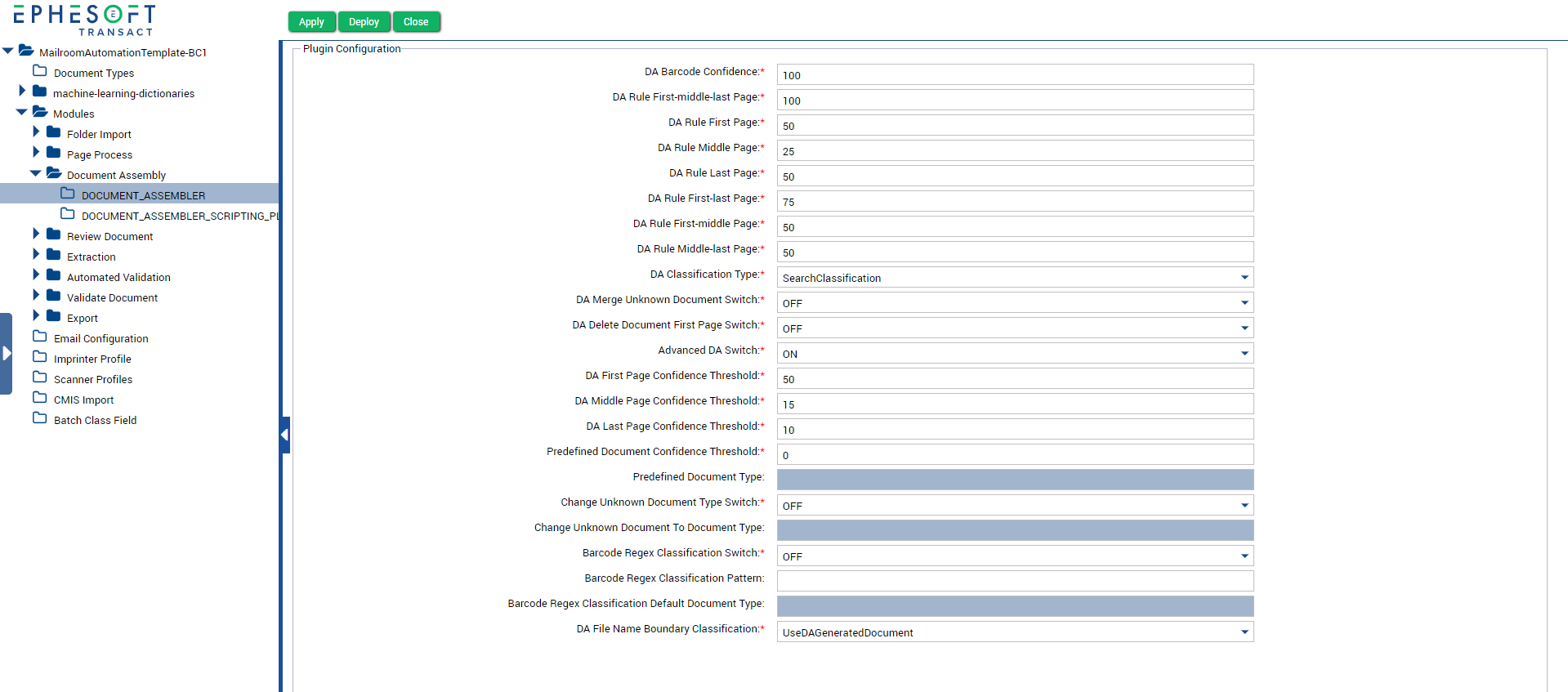
Figure 1. DOCUMENT_ASSEMBLER Plugin
The following table shows the configurable properties and their related values.
| Configurable property | Value options | Description |
| DA Barcode confidence | 0-100 | This field is used to specify the barcode confidence. The confidence value for classified document type in Barcode classification is this value. |
| DA Rule First-middle-last Page | 0-100 | This field is used to specify the confidence for first, middle and last page document. |
| DA Rule First Page | 0-100 | This field is used to specify the confidence for the first page document. |
| DA Rule Middle Page | 0-100 | This field is used to specify the confidence for the middle page document |
| DA Rule Last Page | 0-100 | This field is used to specify the confidence for the last page document. |
| DA Rule First-last Page | 0-100 | This field is used to specify the confidence for the first and last page documents. |
| DA Rule First-middle Page | 0-100 | This field is used to specify the confidence for the first and middle page documents. |
| DA Rule Middle-last Page | 0-100 | This field is used to specify the confidence for the middle and last page documents. |
| DA Classification Type |
|
This value decides the document classification type to be used for classification. |
| DA Merge Unknown Document Switch |
|
This value decides whether the unknown document will be merged with the pre-classified document. |
| DA Delete Document First Page Switch |
|
This value decides whether the first page of the document will be deleted if the document has more than one page. |
| Advanced DA Switch |
|
This value decides whether to run the ADVANCED_DOCUMENT_ASSEMBLER algorithm. |
| DA First Page Confidence Threshold | 0-100 | This field is used in Advanced DA to specify the confidence threshold of the first page for classification into a document. |
| DA Middle Page Confidence Threshold | 0-100 | This field is used in Advanced DA to specify the confidence threshold of the middle page for classification into a document. |
| DA Last Page Confidence Threshold | 0-100 | This field is used in Advanced DA to specify the confidence threshold for the last page for classification into a document. |
| Predefined Document Type | Pre-defined Document Type | This value specifies the document type that a document will be changed to based on the Predefined Document Confidence Threshold. |
| Predefined Document Confidence Threshold | 0-100 | This field is used to specify the threshold confidence below which a document type will be classified into a Predefined Document Type. |
| Change Unknown Document Type Switch |
|
This value decides whether the document classified as UNKNOWN will be changed to the Predefined Document Type. |
| Change Unknown Document To Document Type | Pre-defined Document Type | This value specifies the document type that a document will be changed to based on the Change Unknown Document Type switch. |
| Regex Classification Switch |
|
This value decides whether KV Page process and Barcode Reader results will be compared with the Regex Classification Pattern. If there is a match then the document type is changed to what is specified in the Regex Classification Default Document Type. |
| Regex Classification Pattern | Regex pattern | This value specifies the regex pattern that will be compared to the KV Page process or Barcode Reader values. |
| Regex Classification Default Document Type | Pre-defined Document Type | This value specifies the document type the document will be changed to based on the Regex Classification switch. |
Steps of execution
- This plugin works in the document assembler phase of the Batch Class workflow.
- The plugin uses the page level field results of the Page Processing module as an input and generates the classified documents as an output.
- If the DA Merge Unknown Document Switch is ON, the plugin merges the UNKNOWN type documents into previously classified documents.
Dependency
The plugin assumes the page processing plugins for respective classification types have been executed and the page level fields for each image are populated. The DOCUMENT_ASSEMBLER plugin works on the page level field values for each page and classifies pages into documents.
Troubleshooting
Here are a few common error messages and their root cause:
| Error message | Possible root cause |
| Invalid format of page level fields. DocFieldType found for {Document Assembler Classification Type} classification is null. |
|
| DocumentType name was not found in the database for the page type name | The barcode decoded value is not found as a document type in the Ephesoft Application database. |
| No Document type defined for batch instance | The batch class doesn’t have a document type for classification. |
| Invalid integer for barcode confidence score in the properties file. | An invalid value was used in “DA Barcode confidence” at Ephesoft Admin Screen Configuration. |